This book is pre-release and is an evolving work-in-progress. It is published here for the purposes of gaining feedback and providing early value to those who have an interesting resource oriented computing.
Please send any comments or feedback to: rocbook@durablescope.com
© 2018 Tony Butterfield.
All rights reserved.
Introduction to Resource Oriented Modelling
When approaching the design of a resource oriented system we are faced with many design choices - perhaps more than with any other approach - this can initially be daunting. The root of this abundance of options stems from the constraints that the resource oriented computing architectural style (ROCAS) not only enables, but encourages. This seemingly oxymoronic statement arises because ROCAS provides a foundation which makes building sophisticated, bespoke micro data architectures a realistic proposition — thus liberating you from making an upfront commitment to an existing framework's world view of how your architecture should be and the unforeseen downstream implications.
In the earlier years of computer science, software was built from the ground up, and the development team had full control over all the design options at every level of a system. However, as we strived for greater complexity, we have moved ever more towards frameworks that take away much of the grunt work, allowing development teams to achieve more with less. Despite the very real progress that has been achieved, this has come at a cost. The cost is flexibility. Adopting a framework, or platform means adopting its architectural and technology choices. To be precise, we are talking about macro, server or client level frameworks such as servlet, EJB, Spring, Node.js, not micro frameworks for logging, persistence, or user interface components. This is why adoption of such frameworks is a perilous pursuit - it is very easy to be seduced by their initial high productivity, only to find that you’ve painted yourself into a corner with no option but to hand craft an axe to hack through the wall. Even when a framework is close to perfect for a specific sub-system application, we find that integrating our sub-systems from multiple frameworks into a coherent whole to be a painful task, fraught with opportunities for inconsistency and error. This is because different paradigms don't usually play well together and require masses of glue code, and compromises to work.
So why is ROC different? In a nutshell, the resource oriented approach provides an abstraction that makes it possible to built arbitrarily complex micro data architectures from component building blocks. Contrast this with a framework where components of specific shapes fit into pre-defined slots. In ROC you build the framework with slots where required, and components to fit in your slots. And this is why there are many choices - because you have more freedom - freedom, in effect, to create your own framework.
You may now be asking, “But surely nothing gives more freedom than a Turing machine1 - aren’t most computing environments equivalent in what computation they allow?” That is indeed true, any computing environment that is Turing Complete2 is essentially equivalent in what it can do. Remember though, that ROC provides a high level abstraction, with a focus on creating arbitrarily complex data architectures, whilst still being productive, and keeping those data architectures flexible to change.
We have previously looked in detail at the Resource oriented computing architectural style with a focus on its main characteristics. Now let us take another pass on this topic, focusing on what makes it work so well for micro data architectures. But first what is a micro data architecture?
What Is a Micro Data Architecture Anyway?
Data architecture is a much used term within the broader Enterprise architecture domain. It has come to mean the high level, overall view of an organisation with it’s systems, databases, policies, rules, and standards enumerated - data flows are connected into an enterprise wide relationship graph. On the boundary of this architecture, the interfaces of the organisation are defined, with locations where data flows in and out. This architecture can be thought of on a number of different levels, from the abstract - where it converges with the overall enterprise architecture - down to the physical. At the physical level specific hardware and technology choices are exposed.
Just as the resource abstraction ends at the physical system boundary of the World Wide Web, data architecture ends at the same physical system boundary too - code renders an impenetrable, opaque barrier. Micro data architecture is the term for data architecture which penetrates this barrier, extending down into the flow of data within software systems. In essence it is enabled through introspectable resource oriented approach of ROC. Any code that is there, is hygienically separated from the architecture through the constraint of a uniform interface. This micro data architecture is cleanly defined and exposed. Being broadly applicable across a gamut of scales, the micro data architecture can define high level functionally channeled interfaces between systems and enterprise capabilities down to the intricate details of the mechanisms behind that functionality.
Although the term data architecture has it's origins within enterprise modelling, micro data architectures are suitable choice in many situations. After all, most if not all software systems, capture, generate, transform, and store data as part of their operation even if it is not their primary purpose.
Micro Data Architectures with ROC
In a prior chapter we explored the Resource Oriented Computing Architectural Style. In this section we’ll look specifically at what aspects of this style enable micro data architectures, and the characteristics of that created architecture.
The two key enablers of micro data architecture are, firstly the ROC abstractions aptness for creating custom data architectures and frameworks for development without being prescriptive or too low-level, and secondly, the ability to introspect that architecture to capture and control both structure and runtime state through resources.
ROC - The Framework Building Abstraction
Most, if not all, frameworks necessarily provide a fixed structure in terms of protocols and transports for data in and out, fixed layers of configurable functionality, fixed points to plug in your code and functionality, and fixed choices of programming language. ROC’s deliberate aim is to eliminate as much fixed ground as possible. Transports, clients, architectural layers and programming languages are all unified as endpoints. These endpoints can then be pieced together in a myriad of different configurations through a process called composition.
Unification of all classes of functionality is possible through the uniform interface constraint, but that in itself is not enough. For overlays it is also necessary for symmetry of client and server within the abstraction to facilitate relaying and adaption of requests, as well as address space introspection to allow mirroring and proxying of interfaces. For language runtimes it is necessary for scoping to be liberated from the programming language so that resources with no knowledge of each other can orchestrated together.
In ROC all code is be hidden behind endpoints and representations making a clean separation of architecture from code. Both application code and technology libraries sit comfortably behind whilst the abstraction allows the full power of functional composition, multi-threaded flow control and memory management.
General purpose data types, or as they are called in ROC representations, provide a frank-lingua that allow endpoints with useful functionality to be encapsulated into libraries and to be genuinely reusable. Transreption allows endpoints that where not pre-designed to work together to interoperate. NetKernel provides common representations for a multitude of XML object models, for JSON, bitmap images, binary data and primitives.
ROC - Introspection to the Core
Both static and dynamic metadata is exposed by the ROC abstraction. Spaces show what functionality they contain in endpoints: the interface specifications and documentation. Representations and prototypes are similarly exposed. Overlays show their delegation pathways that link spaces together statically and all spaces registered with kernel can be discovered for cross-system discovery patterns. This meta data is accessed by requests with the META verb which returns representations. Metadata can be used to implemented sophisticated patterns such as dynamic imports and auto-discovered registries. At runtime responses contain metadata about expiration and cost of calculation. The kernel, in its role as intermediary, enables registration of listeners to implement advanced tools such as endpoint profilers and the NetKernel visualiser - a tool which acts as a blackbox recorder capturing requests-response pairs processed and allowing deep post analysis either by humans in development or support roles or by the system itself to analyse behaviour for testing or self-tuning.
Technology vs the Problem Domain
When thinking about the development of a software system, we concern ourselves with both implementing both the problem domain our system addresses, and the runtime tools and technologies that support us and our software system.
Our efforts towards the problem domain consist of implementing the software to model the data and functions of the problem. Any implementation artefacts we create for this will be specific to the problem at hand, though it is possible, and desirable that they be useful to interrelated problems also.
In addition we concern ourselves with any technology necessary to support our problem domain implementation. It is desirable that we can use as much ready built software as possible. Typically this technology includes programming languages, data storage, networking, standard algorithms and data formats. These will either be provided as part of the NetKernel distribution, available as open source libraries, or built as needed. The important distinction, though, is that these technology libraries are not domain specific.
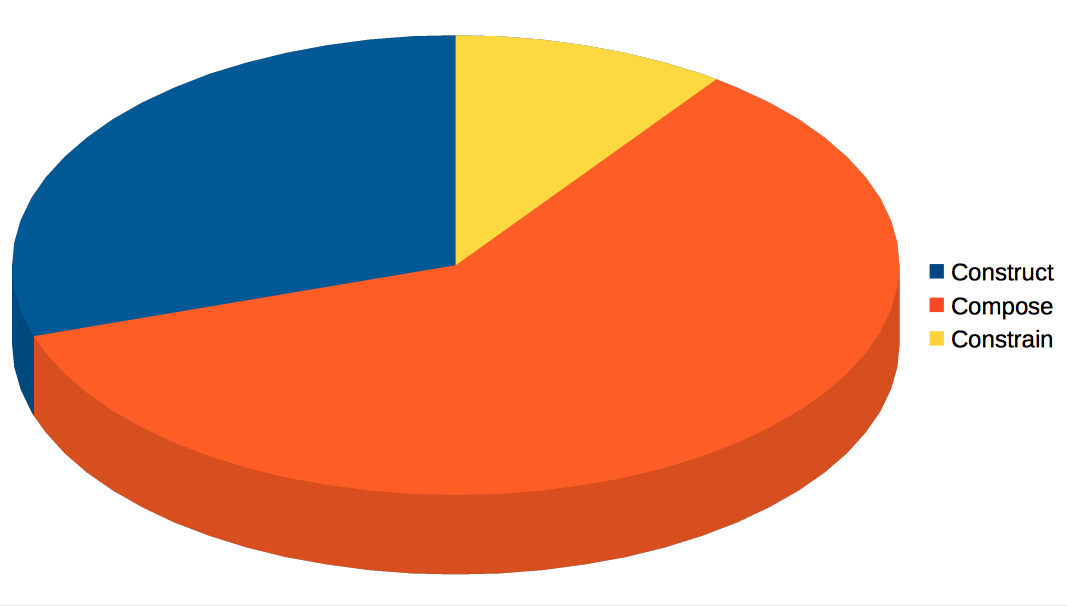
Construct / Compose / Constrain
There are three distinct activities involved in developing a resource oriented system:
- construct - building the endpoints and representations define resources to support our technology choices and problem domain implementation.
- compose - combining and orchestrating our resources to solve problems. This involves crafting address spaces, building a data architecture and sequencing of request invocation using language runtimes.
- constrain - add non functional requirements to a system such as engineering and security.
A typical breakdown of time is 30% construction, 60% composition, and 10% constraint.
Granularity
The resource oriented component model, and the clear distinction of developing the components within construct activity and the combining within the compose activity indicate
ROC as a component model
(maybe this goes into what is ROC section)
- all the components types - representations, accessors, overlays, transreptors, languages, clients, transforms, servers, class libraries
Resource oriented computing can be though of as a component model for building system. It is a component model that attempts to make as much as possible pluggable and as little as possible fixed.
Categories of components:
- representations
- language runtimes
- transports
- clients
- modules
- spaces
- transreptors
- caching
- layer0 - boot, grammars, metadata
granularity of resources - representations, config,