This book is pre-release and is an evolving work-in-progress. It is published here for the purposes of gaining feedback and providing early value to those who have an interesting resource oriented computing.
Please send any comments or feedback to: rocbook@durablescope.com
© 2018 Tony Butterfield.
All rights reserved.
Feel free to skip this chapter if you are not interested in how resource-oriented computing started life and has evolved into what it is today. There should be nothing in this chapter that is prerequisite for understanding the next chapters.
Back in 2000, I'd just wrapped up with a start-up called Component Group. We had been working on a commercialising platform called CDAIS1 which grew out of experience we had working for large utility companies struggling to make object-oriented development work in large teams working with mixed experience developers. The premise was to constrain developers to work within components that communicated via a uniform interface using only XML2. Unfortunately bad timing in the market — the Dot-com bubble3 burst — caused a premature end to that. Fortunately, the skills and domain knowledge would be perfect for what came next.
Inside Hewlett Packard
After Component Group I found work contracting to Hewlett Packard Labs in Filton, Bristol. There I interviewed for a role as a developer in a team of researchers who, as was all the knowledge I obtained from the recruitment agent, where working with XML and Java. During the interview, I realised this was a perfect match. The team had been working on research to find an approach to building software using components that communicated with XML. Their focus was slightly different from that at Component Group; they were looking to build the backend software to XML messaging ecosystems that grew out of industry consortium groups. Many industry groups had established open interoperability schemas using XML at that time, for example for things like procurement and supply chain management.
The research team consisted of Peter Rodgers as project lead, along with Russell Perry and Royston Sellman. All three of them had much experience in industrial research and working with standards bodies; however, they lacked any commercial software development experience. I was that which I, and they, hoped I could bring to the team. When I joined, they had a second generation prototype of what was then called Dexter. Dexter was an XML processing engine that could be configured to run applications. The focus was on using XML and XML processing technologies to create web interfaces without programming as such. XML configuration determined how pre-built components were connected and what configuration those components had.
The killer demo for Dexter at the time was a digital jukebox which streamed out mp3 to clients and let them browse and select tracks via an HTML web interface. The demo showed a third party library (to stream mp3) could be wrapped in an XML interface, and how XML could be used as a data source, the representation for data being processed, and serving the data.
Dexter, at that stage, had an internal architecture modelled on CPUs. Instructions came from an XML document read and processed by a pair of components called the instruction pump and instruction decoder. The instruction pump created a RunnerBean from the XML program specification that was a rudimentary form of DPML (Declarative Processing Markup Language) also called an iDoc (Instruction Document.) The RunnerBean held the execution state such as instruction pointer and any assigned variables.
At this time the IDoc language wasn't too different from the DPML of NetKernel 3 - the instruction names where prepended with "active:" and any arguments were added to the end. There was no pass-by-value abstraction, so any literal values were stored in a component called the Literal pool to make them URI addressable.
These instructions were mapped to accessors using a component called the universal client that consisted of a global registry of mappings of URI regular expressions to Java classes. At this time we formulated the beginnings of the Active URI specification. Data URIs were distinct at this time from instruction URIs, and a component called document IO handled them. This was a thin wrapper around what would become java.net.URI though in Java JDK1.3 this didn't exist yet.
Some of the accessors that we had available in Dexter where XSLT, XQuery, various schema validators, Javascript (from Mozilla), forking4 another iDoc, system introspection and various test, and demo accessors.
It is interesting to note that at this stage of development Dexter didn't have the concept of the request and response or resource representations. All instructions where essentially what we would now call SOURCE except for the special copy instruction that could sink data to accessors that declared they could support it. Rather than representations we had the Java terminology of beans. However, because Dexter was focused on XML these where all XMLBeans - a thin wrapper around W3C DOM object model.
External requests where dealt with in a somewhat similar way to the NetKernel of today, though there was a specific transport manager that was solely responsible for the lifecycle of a globally configured set of transports. At that time we only had an HTTP transport, though Dexter modelled forking as a transport call the internal transport.
Dexter had a cache, and it supported storing the XMLBeans under URI keys. It also could generate a report of what it was holding as an XML document that could be accessed from an iDoc. Management of the cache was very rudimentary. The cache was more like working memory than a cache. If beans were being actively in use by accessors then they where pinned in the cache. Once they were not pinned, a simple scoring mechanism based on time since last access would determine what to cull when the size exceeded a configured maximum.
Overall, the process of handling a request was quite inefficient because each component in the architecture was decoupled from the others by running it on its own thread and having it service its inbound message queue.
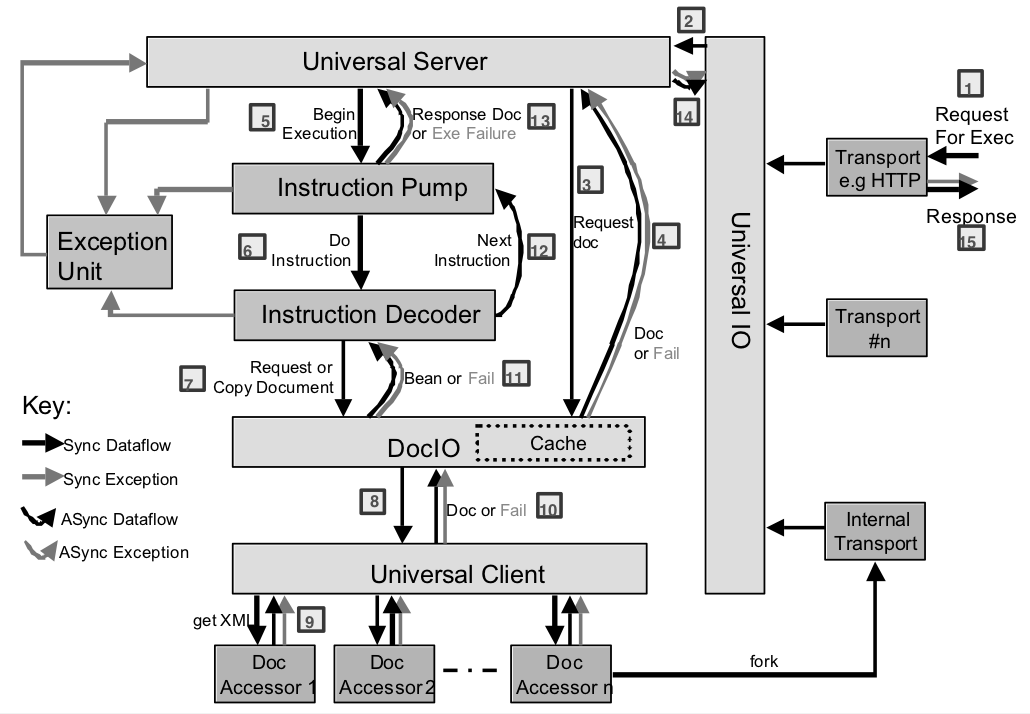 Figure: Dexter component block diagram
Figure: Dexter component block diagram
It is easy for me to look down on the state of Dexter at this time, but the reality is that much innovation happened to get it to that stage. It is only by setting ideas in stone, or rather code, that you have a platform to test your assertions and basis to build higher. We knew that this was a stepping stone to something higher.
Unfortunately, factors outside of our control conspired to end this elevation just as it was beginning. In 2002 Hewlett Packard merged with Compaq, and in forming a new direction, they decided to discontinue their efforts in enterprise middleware. We had initially, as a project, been destined to be part of the Bluestone middleware platform which they had acquired5 in 2000. However, that plan was ended as HP dissolved the Bluestone project in a strategic initiative to move out of middleware. We had a choice to make, find something else to work on or find a way to carry on our path.
1060 Research is formed
Peter Rodgers and I were sure these ideas should not end life in a dusty filing cabinet. We were gaining so much intellectual satisfaction from moving them forward and had such a backlog of avenues to explore. Peter likes to joke that when he suggested the idea of spinning out of HP the rest of the team stood back and I was the only man left standing. The truth is that we both truly believed we had serendipitously discovered something quite momentous.
We departed Hewlett Packard in autumn/fall 2002 to form 1060 Research. At that time we had an uncertain route as Hewlett Packard signed a limited duration intellectual property sharing agreement with us to the Dexter codebase and document repository. The aim was to reach an agreement on spinning out the project. For roughly twelve months after founding, we continued to jointly work on refining and finishing the implementation of Dexter, while working on closing the deal with Hewlett Packard.
Towards the end of this time, we heard, through HP's legal counsel, that all decisions were now needing sign-off from, then CEO, Carly Fiorina. This coincided almost to the day with finalising a release ready version of Dexter. We believed that in a risk-averse corporate culture we would never see the agreement signed. However, disappointment quickly dissipated into excitement as we realised that all the pent-up refinements and ideas could be put into a new clean-room implementation. Within a month we had booted what would become NetKernel.
The irony is that just as we broke free of Dexter implementation, the Hewlett Packard agreement was signed. This agreement still gave us the legal foundation for our endeavour and allowed us to declare the heritage, but we wouldn't ever use a single line of code.
Russell Perry on behalf of Hewlett Packard would write up and publish the research as it stood in a technical report6 to draw a line under their involvement.
At this time I worked with Russell on active URI specification and submission to the IETF7. Active URIs where a schema for encoding function invocation within a URI. We thought that it would be easier to get it established with an HP email address on it. Unfortunately, that was to prove not enough. The process made it clear to me that had already stepped much further away from the web than others were willing. One review criticism we received was:
It sounds to me that you have a system with a resource identifier ... whose meaning depends entirely on the context of the system in which it is placed.
That was precisely the case! However, it was also fundamentally at odds with the global nature of the WWW. Later we would make this context of resolution and evaluation explicit with address spaces.
The First NetKernel
NetKernel, as we called it, was the clean room rewrite of Dexter. We quietly released it as version 2.0.4 in September 2003 after a long summer of coding. Quite why it was versioned as 2.0.4 has been lost, but after a few releases, we reverted to NetKernel 1.0 in January 2004.
NetKernel finally had a proper kernel which processed requests. Functionality was now modularised, with a configuration file specifying the modules that the kernel would load at boot time. Modules where of a fixed architecture as there was no concept of address spaces. Each module has a public set of regular expression matches on resource identifiers that would be rewritten to an internal set of mappings to accessors or imports of other modules.
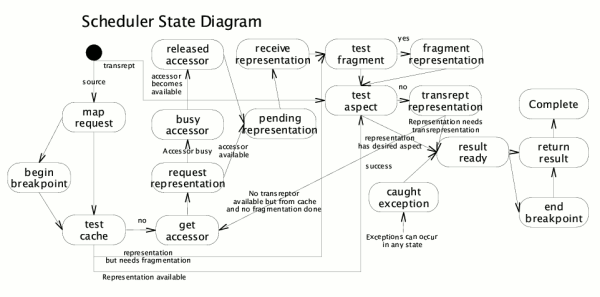 Figure: Kernel request processing state-machine
Figure: Kernel request processing state-machine
Though NetKernel 1 had no explicit address spaces, the concept of super-stack was somewhat similar to resolution scope and would allow requests to accumulate and transfer the scope of which modules the parent request chain had travelled through. This allowed many of the contextual patterns that today's NetKernel allows. However, it made the concept of overlays (endpoints which can channel a set of requests through them and perform some action either inbound or outbound) difficult. Some endpoints did simulate this kind of functionality with nested resource identifiers, but they required multiple modules or awkward rewrite rules in the module definition.
Dexter had been an XML only abstraction, and indeed it required all XML to be represented as DOM (the W3C Document Object Model.) NetKernel was generalised to support any representation type - actually in NetKernel 1 representations were called aspects. One of the first uses of this was to support SAX8 (Simple API for XML) that enabled large documents to be processed by streaming the nodes through endpoints rather than building the entire document in memory. However, the approach also allowed NetKernel to process binary data and images.
To support arbitrary representations, the concept of trans-representation was conceived - initially called transmutation, though it was rapidly renamed. Transreptor endpoints where resolved in modules by matching from and to representational forms in a very similar way to today's NetKernel. An interesting quirk of their operation was that the aspects were accumulated in the response. In today's NetKernel there is a unique response with a single representation for each request. In NetKernel 1 a response could contain multiple aspects, and an endpoint could choose one of them or request an additional on by requesting a transreptor. Because of this, the cache would store all representational forms under the same cache key, and memory management became more difficult.
In some ways, NetKernel 1 had a more sophisticated caching mechanism that exists today. We designed a compound cache where cachlets could be declared for modules. This allowed different cache sizes and mechanisms to be employed in different parts of the system. This flexibility ultimately proved not to be necessary and was later dropped in NetKernel 4.
However many of the essential details of caching where developed at this time: endpoints would accumulate and declare costs that would determine cache-ability merit, and the expiration function became part of the interface of the response metadata. Most of the configuration of response came down to the developer of endpoints. The developer would need to explicitly track dependencies and build an expiration function if that was necessary.
The URL specification has an optional fragment specifier marked by a hash (#) symbol. Typically fragments are a considered a post request transformation of a resource to extract or reference a part of it. In NetKernel 2 we engineered a mechanism to make this a first-class part of the processing abstraction. Fragmentor endpoints would resolve resource identifiers that matched the fragment specification and had appropriate representation types. The idea was explored for the idea of extracting XML fragments and cropping images amongst others. Later we realised that this limited capability to post-transform a resource was an unnecessary complication that was better dealt with as part of the general resource processing engine abstraction.
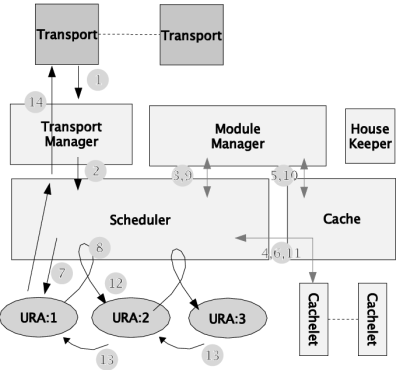 Figure: NetKernel Process Scheduling
Figure: NetKernel Process Scheduling
DPML was moved out of the kernel in NetKernel 1 and became just another endpoint. This allowed a significant simplification of the kernel where much of mechanism of Dexter was consumed with processing the flow and state. It also allowed other languages to be used to program. Once this was established, we explored the polyglot approach to systems development. The kernel exposed an API that these programming languages could use to issue requests and determine the response. We quickly found that this low-level API could be simplified into the XAccessor API to make safer for a developer and require fewer lines of code.
Maturing into Enterprise Grade product
Over the next five years, we continued to evolve our understanding of the domain both through our own thinking and working with early adopters and customers. A lot of the early rough edges concerning usability were smoothed out through new tools and cleanup up APIs.
In this time we transitioned through NetKernel versions 2 and 3. Layers of functionality where accumulated and refined. Many important core ideas were explored and refined such as the NetKernel Foundation API (NKF) to provide a unified developer experience. We added hot deployment of modules, built up the documentation base, and added many new libraries including increasingly sophisticated support for HTTP. To aid developers in this alien environment of resources, we worked hard to provide tools to help, fleshing out many introspection and visualisation tools and even a debugger.
Throughout this period the core abstraction had remained virtually unchanged. The kernel did, of course, change significantly due to the large amount of functionality it contained. It was this fact amongst many others that eventually caused us, seriously, to consider the next major incarnation of NetKernel. Other considerations included:
- the need for address spaces that would unify dynamic value passing on requests with flexible application structure.
- a clean response abstraction where different representations could be managed independently
- automatic determination of response metadata for expiration propagation, evaluation cost, and, most ambitiously, bounding computation scope of request evaluation.
- a metadata model for spaces and resources to support architectural endpoints
- externalising the module and resolution model from the kernel
- a better solution to regular expressions, defining endpoint mappings.
- a better, more consistent to the kernel
- a new default datatype to replace XML for system functionality that has fewer corner cases, higher performance, and more flexibility with nested datatypes.
Resource-Oriented Vision Realised
In mid-2006 I started to put effort into thinking through a way to unify all the competing goals for a new NetKernel. These goals were:
- true ROC abstraction
- address spaces
- asynchronous
- new module implementation supporting address spaces, metadata and grammars
- microkernel - modules outside
- resolution scope
- visualizer
- repository
- metadata
- overlays
- major DPML rewrite
As with NetKernel 1, the core idea and implementation came together quite quickly. What did take time though, was the implementations of standard module, and of DPML. The standard module was a particular challenge because, as we realised later, to make it work as simply as our original vision, it leads to a certain degree of self-reference. This stems from a few sources. For example, the need for prototypes for endpoints that resolve their implementation in the space where they provide their functionality. Also, meta-data driven endpoints such as the dynamic import (which reverses regular imports into a more discovery-like pattern) require spaces, potentially, to import themselves.
By October 2009, after 3 years in gestation, we were finally ready to release NetKernel 4. NetKernel 4 rapidly evolved through NetKernel 5 (released October 2011) and NetKernel 6 (October 2016) gaining refinement and features. It is of this core abstraction that this book will talk about.
-
http://web.archive.org/web/20040405044050/http://www.componentgroup.com/whitepapers/CDAISBusinessOverview.html
↩ -
https://en.wikipedia.org/wiki/XML
↩ -
https://en.wikipedia.org/wiki/Dot-com_bubble
↩ -
Forking is a Unix term for starting the execution of a child program from a parent.
↩ -
http://www8.hp.com/us/en/hp-news/press-release.html?id=302386#.W79SjafMyB0
↩ -
http://www.hpl.hp.com/techreports/2004/HPL-2004-23.html
↩ -
https://tools.ietf.org/id/draft-butterfield-active-uri-01.txt
↩ -
https://en.wikipedia.org/wiki/Simple_API_for_XML
↩